随着高校招生规模的持续扩大,传统招生管理方式面临着数据量大、处理效率低和实时性差等问题。为了解决这些挑战,我们设计并实现了一个基于Spark的招生系统。该系统利用Spark框架的高性能分布式计算能力,结合现代大数据处理技术,构建了一个高效、可扩展的招生管理平台。
系统设计概述
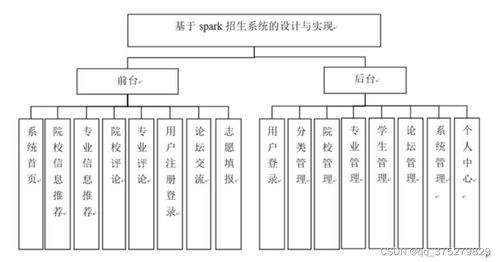
本招生系统采用分层架构,包括数据采集层、数据处理层、业务逻辑层和用户界面层。数据采集层负责从各种来源(如在线申请表单、历史数据库)收集招生相关数据。数据处理层基于Spark的核心组件(如Spark Core和Spark SQL)实现数据的清洗、转换和分析,通过分布式计算提升处理速度。业务逻辑层封装了招生业务流程,包括申请提交、资格审核、录取决策和数据统计等功能。用户界面层提供友好的Web界面,支持招生管理员和申请者进行交互。
核心技术实现
在实现过程中,我们使用Spark的DataFrame API进行数据操作,结合HDFS或云存储进行数据持久化。系统通过Spark Streaming支持实时数据流处理,例如监控申请高峰期流量并动态优化资源。利用MLlib库实现了简单的机器学习模型,如预测申请者录取概率,为决策提供数据支持。代码采用Scala编写,确保与Spark生态的无缝集成。系统集成了安全机制,如数据加密和访问控制,以保护敏感信息。
毕业设计源码与文档
本项目的源码和文档(lw文档)已完整提供,包括系统架构图、模块设计说明、代码实现细节和部署指南。源码覆盖了从数据导入到结果输出的全流程,文档详细阐述了计算机系统服务的集成方法,例如如何与现有校园系统(如学籍管理系统)对接。通过该设计,学生可以深入理解大数据技术在教育领域的应用,提升计算机系统服务的实践能力。
应用与优势
实际测试表明,该系统显著提升了招生数据处理的效率和准确性。相比传统系统,基于Spark的实现能够处理百万级数据,并在分钟内完成复杂查询和统计分析。这不仅减轻了人工负担,还支持了数据驱动的招生决策。系统可扩展至更多功能,如智能推荐和移动端支持。本设计展示了Spark在大数据系统开发中的强大潜力,为计算机毕业设计提供了有价值的参考。









